
티스토리 뷰
구글 창업자인 서르게이 브린과 래리 페이지의 논문, "The Anatomy of a Large-Scale Hypertextual Web Search Engine" 번역
2002-12-3
Abstract
이 논문을 통해 우리는 구글(Google)이라는, 하이퍼텍스트를 통해 나타나는 구조적 특징을 대폭 사용한 대형 검색 엔진의 프로토타입을 제시하고자 한다. 구글은 웹을 능률적으로 긁어와서 인덱싱(색인화)한 다음 (crawling & indexing) 기존의 시스템보다 훨씬 더 만족스런 검색 결과를 나타낼 수 있도록 디자인되었다. 최소 2천 4백만 페이지로 이뤄진 하이퍼링크 데이타베이스와 풀 텍스트로 이뤄진 구글의 프로토 타입은 http://google.stanford.edu의 주소로 이용해 볼 수 있다.

검색엔진을 제작한다는 것은 상당히 도전적인 과제다. 검색 엔진은 수억에서 수십억 개의 웹 페이지와 수억-수십억 개의 용어들을 함께 인덱싱한다. 또한 검색엔진은 매일 수천 만 개의 질의어에 응답한다. 웹 기반의 대형 검색엔진의 중요성이 분명함에도 불구하고 이에 대해 학문적으로 연구된 바는 거의 없다. 게다가 웹의 분화와 테크널러지의 발달이 매우 빠르기 때문에 오늘 웹 검색엔진을 만드는 것은 3년 전에 만드는 것과 전혀 다르다. 이 논문에서 우리는 우리가 만든 대형 웹 검색엔진에 대해서 자세하게 묘사하고자 한다.(현 시점까지 이렇게 자세한 내용이 공개된 것은 최초라 할 수 있다.)
전통적인 검색 기술을 거대한 크기의 데이타에 맞게 확장하는 것에서 초래되는 문제들은 별개로 하더라도, 보다 나은 검색 결과를 나타낼 수 있도록 하이퍼텍스트에 나타나는 부가적인 정보를 이용하는 문제 같은 새로운 기술적 과제들이 있다. 이 논문에서는 이와 같은 하이퍼텍스트에 존재하는 부가적인 정보를 실제 사용 가능한 대형 시스템을 구축하는 데 어떻게 활용할 수 있는가라는 문제에 대한 해결책을 제시한다. 또한 우리는 웹처럼 아무나 원하는 것을 출판할 수 있는 통제되지 않는 하이퍼텍스트 문서 컬렉션(uncontrolled hypertext collections)을 어떻게 효과적으로 다룰 수 있을지의 문제도 살펴본다.
1. 개괄
웹은 정보검색(IR; Information Retrieval)에 새로운 과제를 안겨줬다. 웹에 존재하는 정보들은 매우 빠르게 늘어나고 있다. 그리고 웹에서 무엇인가를 찾는 것에 익숙하지 못한 새로운 사용자들의 숫자도 급속하게 늘어나고 있다. 사용자들이 웹 써핑을 할 때 대개 링크 그래프(link graph)를 이용하는 경향이 크다. 사람이 직접 만든 목록 중 아주 높은 품질의 목록(야후! 같은)에서 출발하거나 검색엔진을 이용한다. 사람이 직접 유지관리하는 목록은 보편적인 주제를 효과적으로 커버할 수 있다는 장점이 있지만, 주관적이기 쉽고 구축/유지 비용이 매우 높고, 개선이 느리고 모든 특이한 주제를 커버할 수 없다는 단점이 있다. 한편 키워드 매칭(keyword matching)을 기반으로 하는 자동화된 검색엔진(automated search engine)은 대개 너무 많은 낮은 질의 맷치를 결과로 돌려주는 경우가 잦다. 게다가 어떤 광고인들은 자동화된 검색엔진이 엉뚱한 결과를 나타낼 수 있는 방법을 사용해서 사람들의 주의를 끌어가려는 시도를 한다. 우리는 이와 같은 기존 시스템의 여러가지 문제점들을 해결한 대형 검색엔진을 구축했다. 특히 우리 검색엔진은 훨씬 높은 수준의 검색 결과를 제공하기 위해 하이퍼텍스트에 존재하는 부가적인 구조를 대폭 사용했다. 우리는 우리 시스템 이름을 '구글'(Google)로 택했는데, 이것은 10100 또는 'googol'을 뜻하는 일반적인 철자이기 때문이기도 하고 매우 큰 스케일의 검색엔진을 구축하겠다는 우리의 목표와 잘 부합되기 때문이기도 했다.
1.1 웹 검색엔진의 확장: 1994 - 2000
검색엔진 기술은 웹의 성장세에 맞춰 극적으로 확장되어 왔다. 1994 년 최초의 검색엔진 중 하나인 World Wide Web Worm(WWWW)은 110,000 페이지의 웹문서 및 웹을 통해 접근가능한 문서를 색인화(indexing;인덱싱)한다. 1997년 현재, 최고 수준의 검색엔진들은 2백만 문서에서(WebCrawler) 1억 개의 문서까지 인덱싱했다고 주장하고 있다. 2000년 말쯤이면, 약 10억 개 이상의 문서에 대한 포괄적인 인덱스(comprehensive index)가 만들어질 것으로 예상되고 있다. 검색엔진이 다루는 질의어(queries)의 숫자 역시 믿기지 않을 정도로 성장해 왔다. 1994년 3,4월경, WWWW은 매일 평균 1500여 개의 질의어를 받았었다. 그런데 1997년 11월, 알타비스타(AltaVista)의 주장에 따르면 매일 약 2천만 개의 질의어를 처리하고 있다 한다. 웹 사용자가 더욱 늘어나게 됨에따라, 2000년 말쯤에 이르면 탑 검색엔진들은 매일 평균 약 수억 개의 질의어를 다루게 될 것이다. 우리 시스템은 검색엔진 기술을 위와 같은 놀라운 크기의 숫자를 다룰 수 있게 확장하는 데 있어 발생하는 많은 문제점들을 그 질적인 측면에서나 확장성 면에서나 잘 해결해 보겠다는 목표를 갖고 있다.
1.2 구글(Google): 웹과 함께 확장한다
오늘날의 웹 정도를 포괄하는 검색엔진을 만드는 일도 많은 도전적 과제를 해결해야 한다. 웹 문서들을 모으고 최신 상태로 유지하기 위해서는 빠른 속도의 크롤링 기술(crawling technology)이 필요하다. 그리고 색인(index)을 저장하고 때로는 문서 자체를 저장하기 위해 저장 공간은 반드시 효율적으로 사용되어야만 한다. 인덱싱 시스템은 수백 기가바이트의 데이타를 효율적으로 처리할 수 있어야만 하고 질의어 역시 초당 수백, 수천 개 이상의 빠른 속도로 처리되어야 한다.
이런 과제들은 웹이 계속 성장해 감에 따라 갈수록 어려워지고 있다. 하드웨어 성능과 비용이 극적으로 좋아지고 있는 것은 이런 문제점들을 어느 정도는 상쇄한다. 그러나 거기에도 주목할 만한 예외가 있다. 디스크 검색 속도(disk seek time)라든지 운영체계의 강력함(robustness)은 별로 개선되지 못하고 있다. 구글을 디자인함에 있어, 우리는 웹의 성장 속도와 테크널러지의 변천 속도 모두를 고려해 왔다. 구글은 극단적으로 큰 데이타 셋(data sets)을 위해서도 충분히 확장될 수 있도록 디자인되어 있다. 인덱스를 저장하기 위한 저장 공간을 효율적으로 사용할 뿐만 아니라 구글의 데이타구조는 빠른 억세스, 효율적인 억세스에 적합하도록 최적화되어 있다. (4.2 섹션에서 자세히 다룬다) 그리고 HTML이나 텍스트를 저장하고 인덱싱하는 비용은 그 양이 늘어남에 비해 상대적으로 감소할 것으로 예상된다. 이것은 구글과 같은 중앙집중식 시스템의 확장성에 좋은 영향을 미치게 된다.
1.3 디자인 목표
1.3.1 검색 품질의 개선
우리의 주된 목표는 웹 검색 엔진의 질적인 면을 개선하는 것이었다. 1994년 당시만 해도 완전한 검색엔진 인덱스를 갖춤으로써 무엇이든 쉽게 찾을 수 있을 것이라 믿는 사람들이 있었다. "Best of the Web 1994 -- Navigators"에는, "최상의 네비게이션 서비스는 웹상의 거의 모든 것을 쉽게 찾을 수 있도록 해줘야 한다 (일단 모든 데이타가 입력되고 나면)" 라고 실려있었던 것이다. 하지만 1997년의 웹은 그 전과 전혀 다른 양상이다. 최근 검색 엔진을 사용해 본 사람이라면 누구나 인덱스 자체의 완전성이 검색 결과의 품질을 결정하는 유일한 요소가 아님을 얘기할 것이다. "쓰레기 검색 결과"(Junk results)가 원하는 결과를 압도해버리는 것이 드물지 않다. 사실, 1997년 11월 현재, 검색창에 검색엔진 자신의 이름을 입력했을 때 탑 10 결과 내에 자신의 이름이 들어있는 검색 엔진은 상위 4 개의 상업적 검색 엔진에 불과하다.
이것의 주된 원인은, 문서의 수는 기하급수적으로 증가해온 반면 사용자가 문서를 찾는 능력은 그렇지 못했기 때문이다. 사람들은 여전히 검색 결과 중 수십 개 정도만을 보려한다. 그러므로 문서 모음(이하 컬렉션, collection)의 크기가 증가함에 따라 대단히 높은 프리시젼(precision)을 가진 툴이 필요해진다. (precision은 검색 결과 중 실제 검색어와 관계되는 결과의 비율. 역자주)
사실 우리는, "관계되는"이라는 단어의 의미를 아주 높은 수준으로 규정하려 했는데 그 이유는 '약간' 관계되는 문서들만 해도 수만 개 이상이기 때문이다. 극도로 높은 수준의 프리시젼은 심지어 리콜(recall)을 희생해서라도 달성해야 할 만큼 중요하다. (recall은 관계되는 문서 중 얼마나 많은 것을 찾아낼 수 있느냐를 의미)
최근, 하이퍼텍스트적인 정보를 보다 더 많이 이용함으로써 검색이나 다른 부문의 기능을 개선할 수 있을 것이라는 낙관적인 전망이 많이 나오고 있다. 특히 링크 구조와 링크 텍스트는 "관계성 판단"(relevance judgement)과 질적인 필터링에 있어서 많은 정보를 제공할 수 있다. 구글은 그 링크 구조와 앵커 텍스트(anchor text)를 사용하고 있다.
역자주 : recall과 precision은 정보검색(IR)에서 중요한 성능 측정 기준으로 사용하는 지표입니다. precision은 검색 결과 중에 실제로 '관계되는' 문서가 몇 개인가를 의미합니다. 즉, 결과의 '정확도'입니다. recall은 검색어와 관계되는 문서 전체 중에 몇 개를 찾아내느냐입니다. precision은 보통 상위 몇 위까지 중 관계되는 문서가 몇 개인가 형태로 평가합니다. 예를 들어, 어떤 컬렉션의 총 문서 갯수는 100 개이고 이 중에 '사과'와 관계되는 문서가 30 개 있다고 합시다. 질의어 '사과'에 대해서 어떤 검색 시스템이 총 15 개의 결과를 되돌려 주었고 상위 10 위까지의 결과 중 실제로 사과와 관계되는 문서가 8 개였다면 precision과 recall은 이렇게 계산합니다.
상위 10 위에서의
precision = 8 / 10 = 0.8
recall = 15/30 = 0.5
논문은, 웹 검색의 경우 리콜이 극도로 높고 (대개 검색결과가 수만 페이지 이상이기 때문에) 사용자들은 상위 몇 개만을 보려하기 때문에 프리시젼이 극도로 높아야만 한다는 것을 얘기하고 있습니다. 소규모 도서관 정보 검색 시스템이라면 얘기가 전혀 다릅니다. 관계되는 모든 서적을 다 찾아내는 것이 더 중요할 수 있습니다. 그 때는 리콜이 더 중요합니다. 그렇다면 리콜과 프리시젼은 어떤 관계일까요?
1.3.2 검색 엔진에 관한 학술 연구
웹은 자체 성장속도 뿐만 아니라 상업화의 속도도 엄청나게 빠르다. 1993 년에는 .com 도메인이 전체의 1.5%였다. 그러던 것이 1997 년에는 전체의 60%를 차지하고 있다. 검색엔진 역시 학술적 영역에서 벗어나 상업화되어 왔다. 현재까지 기업체에서 개발한 검색엔진의 대부분은 기술적인 디테일을 거의 발표하지 않고 있다. 검색 엔진 기술은 장막에 가려진 채 광고 지향적인 것으로 남아있는 실정이다. 우리는 구글을 통해서 검색 엔진 개발과 이해를 보다 학술적인 영역으로 끌어와 보고자 했다.
또 하나 중요한 디자인 목표는 상당한 숫자의 사람들이 실제로 사용할 수 있는 시스템을 구축해 보자는 것이었다. 구축한 시스템이 실제로 사용되어야 한다는 점이 중요한데 그 이유는, 오늘날의 웹 시스템에서 만들어질 수 있는 대용량의 유시지 데이타(usage data)를 활용함으로써 아주 흥미로운 연구가 이뤄질 수 있다고 생각하기 때문이다. 예를 들면 매일매일 이뤄지는 수억 건의 검색 행위와 관계되는 데이타가 그렇다. 하지만 이런 데이타는 확보하기가 매우 어렵다. 상업적 가치가 높다고 여겨져서 공개되지 않기 때문이다.
마지막 디자인 목표는 대용량 웹 데이타상에서 많은 새로운 연구 활동이 이뤄질 수 있도록 그 기반을 구축해 보겠다는 것이었다. 새로운 연구에 사용되게 만들기 위해 구글은 크롤링한 실제 문서 그 자체를 압축된 형태로 저장한다. 구글을 디자인함에 있어 우리의 주된 목표 중 하나는 다른 연구자들이 웹의 상당한 부분을 처리해서 흥미로운 결과를 내놓은 것에 쉽게 참여할 수 있는 길을 터주자는 것이었다. 구글 시스템을 가동한 지 얼마되지 않았음에도 구글에 의해 생성된 데이타베이스를 이용한 여러 편의 연구가 이미 발표되었고 또한 많은 연구가 현재 진행중이다. 또 하나의 목표는 구글을 일종의 우주 실험실과 같은 환경으로 만들어서 다른 연구자들이나 학생들이 대형 웹 데이타상에서 여러가지 흥미로운 실험을 제안하고 실행해 볼 수 있게 하겠다는 것이다.
구글 검색 엔진은 검색 결과가 높은 프리시젼을 갖도록 두 가지 중요한 특징을 부여했다. 첫째, 구글은 개별 웹 페이지 품질을 순위 매기기 위해 웹의 링크 구조를 이용한다. 이 랭킹은 페이지랭크(PageRank)라 일컬어지며 다른 논문에서 자세히 설명했다. 둘째, 구글은 검색 결과를 개선하기 위해서 링크를 사용한다.
2.1 페이지랭크(PageRank) : 웹에 순서를 매긴다
웹의 인용(링크) 그래프는 기존의 웹 검색 엔진들이 거의 사용하지 않고 있는 중요한 자원 중 하나이다. 우리는 총 5억1800만 개의 하이퍼링크를 담고 있는 링크 지도를 만들었는데 이것은 전체 웹의 상당 부분을 포괄하는 것이다. 이 지도를 이용하면 어떤 웹 페이지의 "페이지랭크" 값을 빠르게 계산할 수 있다. 페이지랭크는 일반적인 사용자가 생각하는 특정 페이지의 중요성과 잘 상응하는 인용 중요성의 객관적인 측정치다. 인간 판단과의 이런 연관성 때문에 페이지랭크는 웹 키워드 검색 결과를 순위 매기는 데 있어 최상의 수단이 된다. 대부분의 일반적 검색어에 있어서, 문서 제목과 검색어가 일치하는지만을 평가하는 단순한 텍스트 매칭 검색 엔진을 이용한 결과에서도, 그 결과를 페이지랭크로 순위를 매기는 경우 상당한 성능을 보여준다. 물론 구글 시스템과 같이 완전한 텍스트 검색을 수행하는 시스템에서도 페이지랭크는 매우 큰 도움을 준다.
2.1.1 페이지랭크 계산 방법
학술 문헌 인용 방식을 웹에도 적용해보려는 시도가 있어 왔는데 대개 어떤 페이지의 인용 횟수(백링크; back link)를 세는 방식으로 이뤄진다. 어떤 페이지가 얼마나 많이 인용(참조)되고 있는가를 셈으로써 그 페이지의 중요성이나 품질을 추정해볼 수 있는 것이다. 페이지랭크는 이 아이디어를 더욱 확장해서 단순히 모든 링크를 세는 것에서 한 발 더 나아가 그 링크가 어떤 페이지로부터 왔는지를 차별화했고, 링크를 하고 있는 페이지로부터 외부로 나가는 총 링크 갯수로 노멀라이징(normalizing)했다. 페이지랭크는 다음과 같이 정의된다:
페이지 A를 가리키는 다른 페이지들이 T1, T2, ... Tn 까지 있다고 하자. ( = T1,...Tn은 페이지 A를 인용)
퍼래미터 d는 damping factor로 0에서 1 사이의 값을 갖는다. 우리는 보통 d = 0.85로 했다. d값에 관해서는 다음 섹션에서 다룬다.
C(A)는 페이지 A에서 밖으로 나가는 링크의 갯수다. 이때 A 페이지의 페이지랭크 PR(A)는:
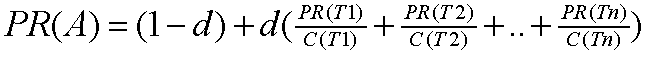
페이지랭크 PR(A)는 단순한 반복 알고리듬(iterative algorithm)을 이용해서 계산할 수 있으며, 그 값은 웹 링크를 노멀라이징해서 행렬로 바꾸었을 때 주고유벡터(principal eigenvector)에 해당한다. 또한 2천6백만 페이지의 페이지랭크는 중간 크기의 웍스테이션에서도 몇 시간 정도면 계산할 수 있다. 이에 관해서는 이 페이퍼의 범위를 벗어나는 많은 세부사항이 있다.
2.1.2 직관적 정당화
페이지랭크는 사용자 행동을 모델링한 것으로 생각해볼 수 있다.
"랜덤 써퍼"가 한 명 있다고 하자. 이 사람은 무작위로 선택한 어떤 웹 페이지에서 출발해서 백버튼을 누르지 않고 계속 링크를 따라 클릭해 나간다. 그러다가 지루해지면 또 다른 무작위로 선택된 페이지에서 써핑을 시작할 것이다. 랜덤 써퍼가 특정 페이지를 방문할 확률이 바로 그 페이지의 페이지랭크다. 그리고 d damping factor는 랜덤 써퍼가 어떤 페이지를 읽다가 지루해져서 또 다른 랜덤 페이지를 찾게될 확률을 뜻한다. 페이지랭크의 변형된 형태 중에서 중요한 것 중 하나가 댐핑 팩터(damping factor) d를 특정 페이지 하나 또는 일군의 페이지에만 선택적으로 적용하는 것이다. 이렇게 함으로써 사용자화(personalization)가 가능하며 랭킹을 올리기 위해 교묘하게 조작하는 것을 사실상 불가능하게 만들 수 있다. 그 외에도 많은 페이지랭크의 확장이 있다.
또 하나의 직관적인 정당화는, 페이지랭크가 올라가기 위해서는 많은 페이지가 어떤 한 페이지를 가리켜야 하거나 특정 페이지를 가리키는 페이지 그 자체의 페이지랭크 값이 커야 한다는 점이다. 직관적으로도 웹상의 여러 곳에서 인용되고 있는 페이지는 살펴볼 만한 가치가 있다는 의미이므로 쉽게 이해가 된다. 또한 Yahoo!와 같은 중요한 곳에서 인용이 되고 있다면 링크가 오직 한 개뿐일지라도 그 페이지는 살펴볼 가치가 있을 것이다. 어떤 페이지가 품질이 낮거나 링크가 깨져있다면, Yahoo!같은 곳에서 그 페이지로 링크를 걸어놓지 않을 것이기 때문이다. 페이지랭크는 이 두 가지 경우 모두를 잘 다루고 있으며 양자 사이의 모든 부분도 웹의 링크 구조를 통해 가중치를 재귀적으로 전파시켜 나감으로써 잘 다루고 있다.
2.2 앵커 텍스트(Anchor Text)
우리 검색 엔진은 링크의 텍스트 그 자체를 특별하게 다룬다. 대부분의 검색 엔진들은 링크의 텍스트를 링크를 담고 있는 그 페이지와만 연관시킨다. 우리는 더 나아가 링크가 가리키는 페이지까지 링크의 텍스트와 연관시킨다. 이것은 여러가지 장점이 있다. 첫째, 앵커는 종종 그 링크가 담겨있는 페이지보다 그 링크가 가리키는 페이지에 대한 보다 정확한 설명을 담고 있는 경우가 많다. 둘째, 일반적인 텍스트 검색 엔진이 인덱싱할 수 없는 이미지나 프로그램, 데이타베이스로의 앵커(링크)도 존재할 수 있다. 그러므로 앵커를 활용하면 실제로 크롤링되지 않은 웹 페이지들까지 찾아낼 수 있다. 물론 크롤링되지 않은 페이지들이 문제를 일으킬 수 있다는 점은 주의해야 한다. 이 페이지들은 사용자에게 결과로 뿌려주기 전에 유효성을 먼저 테스트 해야한다. 심지어 실제 존재하지 않는 페이지인데도 가리키는 링크가 있기 때문에 반환될 수도 있다. 하지만 이런 검색 결과를 분류하는 것이 가능하므로 특별한 문제를 일으키는 경우는 거의 없다.
앵커 텍스트를 그 앵커가 가리키는 페이지로 전파시켜 나간다는 아이디어는 World Wide Web Worm 검색 엔진에서 구현되었었다. 앵커 텍스트가 텍스트가 아닌 정보를 검색하는데 도움이 되었고, 검색 엔진이 다운로드한 문서보다 훨씬 더 많은 부분을 커버할 수 있게 확장해주기 때문이다. 앵커 텍스트를 효율적으로 사용하려면 대용량의 데이타를 처리해야만 하기 때문에 기술적으로 까다롭다. 우리는 크롤링한 2400만 페이지에서 약 2억5900만 개 이상의 앵커를 인덱싱할 수 있었다.
2.3 다른 특징들
페이지랭크 기술과 앵커 텍스트를 사용한다는 점 외에 구글은 몇 가지 다른 특징을 가진다. 첫째, 구글은 모든 힛(hit)에 관한 위치 정보를 저장하기 때문에 검색 時 근접도를 광범위하게 활용한다. 둘째, 구글은 어떤 단어의 폰트 크기와 같은 시각적인 세부 요소를 추적한다. 폰트 싸이즈가 큰 단어나 볼드체로 된 단어는 그렇지 않은 단어에 비해 더 높은 가중치가 부여된다. 셋째, 구글은 완전한 HTML도 저장하기 때문에 이를 이용할 수 있다.
3. 관련 연구
웹 상의 검색 연구는 역사가 얼마 되지 않는다. World Wide Web Worm (WWWW) 검색 엔진이 대표적인 최초의 검색엔진이다. WWWW을 기점으로 그 뒤에 몇 개의 학술적 목적의 검색엔진이 나타났다. 웹의 성장세나 검색 엔진의 중요성에 비해 현대적 웹 검색엔진에 관한 문서는 거의 없는 실정이다. Michael Mauldin(Lycos 의 Chief Scientist)씨는, "라이코스를 포함한 여러 서비스들은 자기 데이타베이스의 디테일들을 엄격하게 감추고 있다"고 밝혔다. 하지만 검색엔진의 특정 기능에 관해서는 상당한 양의 연구가 진행되어 왔다. 특히 기존의 상업적 검색엔진을 이용한 결과물을 후처리(post processing)한 것에 관한 부문이 두드러진다. 반면 정보검색(IR, Information Retrieval)에 관해서는, 특히 잘 조절되고 있는 컬렉션을 대상으로한 것은, 이미 많은 연구가 나와있다. 다음 두 섹션에서, 우리는 이들 연구를 웹에서 보다 더 잘 동작하도록 확장하는 방법을 살펴볼 것이다.
3.1 정보 검색
정보 검색 시스템에 관한 연구는 오래 전부터 있어 왔으며 잘 정리되어 있다. 하지만 대부분의 정보 검색 시스템에 관한 연구는 소규모의 잘 통제되고 있는 동질적인 컬렉션(a small well controlled homogenous collection)을 대상으로 하고 있다. 예를 들면 과학 논문이나 서로 연관되는 뉴스 기사들을 대상으로 하고 있다. 실제 정보 검색의 가장 대표적인 벤치마크로 사용되는 TREC(Text Retrieval Conference)의 경우 아주 작은 크기의 잘 통제되어 있는 컬렉션을 이용한다. "초대형" 벤치마크라고 해 봐야 겨우 20기가 바이트에 지나지 않는다. 반면 우리가 모아놓은 2천400만 개의 웹 페이지는 147기가 바이트에 이른다. TREC에서는 좋은 결과를 보이더라도 웹에서는 좋은 결과를 나타내지 못하는 경우가 많다. 예를 들어, 표준적인 벡터 공간 모형(Vector Space Model)은 질의어와 문서를 단어 빈도에 의거한 벡터로 파악해서 질의어에 가장 근접한 문서를 되돌려주는 방식이다. 하지만 웹에서 벡터 공간 모형을 사용하면 질의어 외에 몇 단어 없는 매우 짧은 문서가 반환되는 경우가 많다. 메이져 검색 엔진에 "Bill Clinton"이라는 질의어를 넣어 보면 "Bill Clinton Sucks"라는 문장과 사진이 담겨 있는 페이지만 결과로 되돌려 준다. 어떤 사람은 질의어 외에 부가적으로 단어를 추가해서 사용자가 찾는 단어를 더 정확하게 표현할 수 있는것 아니냐고 주장한다. 우리는 그런 주장에 전혀 동의하지 않는다. 사용자가 "Bill Clinton"이라는 질의어를 입력했다면 당연히 합리적으로 받아들일 수 있는 결과를 얻어야 한다. 웹에는 그 주제에 관한 엄청나게 많은 고품질의 페이지가 있기 때문이다. 이런 예들을 보면서 우리는 표준적인 정보 검색 연구를 웹에 효과적으로 적용하기 위해서는 더욱 많은 확장이 필요하다고 생각하게 되었다.
3.2 웹과 잘 통제되는 컬렉션 사이의 차이점들
웹은 전혀 통제되지 않는 이질적인 문서들로 이뤄진 거대한 컬렉션이다. 웹상의 문서는 문서 내부적으로도 극단적으로 다양할 뿐만 아니라 문서 외부적인 메타 정보 역시 매우 다양하다. 예를 들어, 여러 웹 문서들은 내부적으로 사용 언어 측면에서 다르고 (인간의 언어 측면에서도 그렇고 컴퓨터 언어 측면에서도 그렇다), 어휘에 있어서도 다르고 (이메일 주소, 링크, 우편 번호, 전화 번호, 제품 번호 등), 포맷이나 유형 면에서도 다르며 (텍스트, HTML, PDF, 이미지, 싸운드) 심지어 어떤 문서들은 컴퓨터에 의해 생성되고 있는 것이다. (로그 파일, DB 로부터 출력된 내용)
메타 정보의 경우도 마찬가지다. 우리는 외부 메타 정보를 어떤 문서 내부에는 담겨 있지 않은 정보로, 그 문서 자체에 관해 유추할 수 있는 정보로 정의한다. 외부 메타 정보에는 그 페이지의 명성, 업데잇 빈도, 품질, 인기도 또는 유시지(usage), 그리고 인용 등이 있다. 외부 메타 정보는 그 잠재적 소스가 다양할 뿐만 아니라, 측정값 역시 큰 차이가 난다. 야후! 홈페이지와 수십 년된 낡은 기사를 비교해 보자. 야후!는 매일 수백만 페이지뷰 이상을 받지만, 후자의 경우는 십 년만에 한 번 찾아지거나 할 것이다. 이 경우 사용도는 현격하게 차이가 난다. 그리고 검색 엔진은 이 둘을 전혀 다른 방식으로 다뤄야 한다는 것 역시 당연하다.
잘 통제되는 컬렉션과 웹이 크게 다른 또 다른 점은, 웹에서는 누가 무엇을 올려놓을지를 조절할 방법이 사실상 없다는 점이다. 무엇이든 퍼블리슁할 수 있다는 웹의 유연성이 트래픽을 안내하는 검색 엔진의 엄청난 영향력과 맞물리면, 검색 엔진을 교묘하게 조절해서 이득을 취해가려는 회사들이 심각한 문제가 된다. 이런 점들은 전통적인 폐쇄적 정보검색 시스템에서는 전혀 문제가 되지 않았었다.
웹 검색 엔진의 경우 메타 데이타를 사용하려는 시도가 거의 실패로 돌아갔다는 점 또한 특기할 만하다. 실패한 이유는 검색 엔진을 악용하기 위해 메타 정보가 남용되었기 때문이다. 심지어 메타 태그를 이용, 검색 엔진을 조작하는 쪽으로 특화한 회사들도 상당수 존재할 정도이다.
4 시스템 해부학(System Anatomy)
먼저, 아키텍쳐에 관해 상위 수준에서 논의를 해보고자 한다. 그 다음으로, 주요 데이타 구조에 관해 보다 심층적인 묘사를 할 것이다. 마지막으로, 크롤링(crawling), 인덱싱(indexing), 서칭(searching) 같은 주요 애플리케이션들을 자세히 살펴보겠다.
4.1 구글 아키텍쳐 개괄 (Google Architecture Overview)
이 섹션에서는, 그림 1에 표현된 것과 같은 전체 시스템이 어떻게 동작하는지에 관해 상위 수준의 개괄을 살펴볼 것이다. 이후 섹션에서는 본 섹션에서 언급하지 않은 애플리케이션들과 데이타 구조에 관해 다룬다. 구글은 효율성을 위해 대부분 C나 C++ 언어로 만들어졌으며 솔라리스나 리눅스에서 실행할 수 있다.
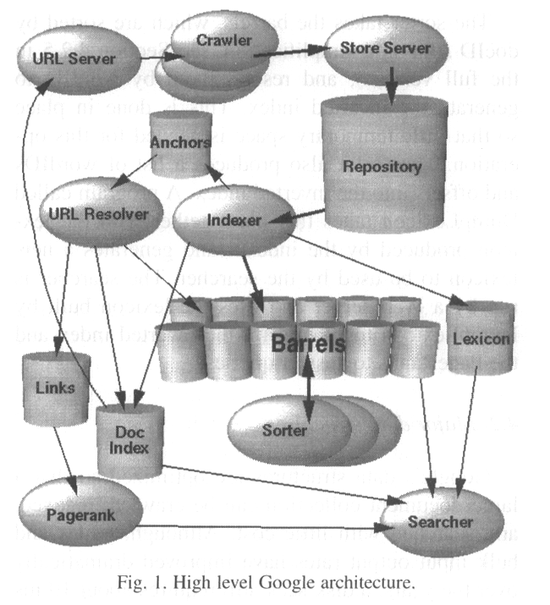
구글에서는, 웹 크롤링(웹 페이지를 다운로드하는 것)은 분산된 여러 개의 크롤러(crawler)에 의해 수행된다. 크롤러가 가져 올 URL의 목록은 URL서버가 제공한다. 그렇게 해서 가져 온 웹 페이지는 저장서버(storeserver)로 보내진다. 그러면 저장서버는 웹 페이지를 압축해서 리파지토리(repository;저장소)에 저장한다. 모든 웹 페이지는 연관된 ID 넘버가 있다. 이 숫자는 docID라고 하며 웹 페이지로부터 새로운 URL이 추출될 때마다 할당되는 숫자다. 인덱싱(indexing;색인) 기능은 인덱서(indexer;색인 애플리케이션)와 소터(sorter; 정렬 애플리케이션)에 의해 수행된다. 인덱서는 여러 가지 기능을 수행한다. 리파지토리를 읽고, 문서 압축을 풀고, 이를 분석한다. 각각의 문서는 '히트(hits)'라고 하는 출현 단어 집합으로 변환된다. 히트에는 단어와, 그 단어의 문서 내 위치, 폰트 크기의 근사치, 대소문자 구분 등이 기록된다. 인덱서는 이들 히트를 "배럴(barrels)"로 분산 저장하고, 부분적으로 정렬된 포워드 인덱스(forward index)를 만들어낸다. 인덱서는 또 하나의 중요한 기능을 수행한다. 각 웹 페이지에 있는 모든 링크를 추출해서 링크에 관한 중요 정보를 앵커파일(anchors file)에 저장한다. 앵커 파일은 각 링크가 어디서부터 와서 어디를 가리키는지, 그리고 그 링크의 텍스트 등을 결정할 수 있는 충분한 정보를 담고 있다.
그 앵커 파일은 URL리졸버(URL resolver;URL처리 애플리케이션)가 읽어들여서, 상대 주소(relative URLs)를 절대 주소(absolute URLs)로 변환한 다음 docID로 바꾼다. URL리졸버는 앵커가 가리키는 docID의 포워드 인덱스에 앵커 텍스트를 집어 넣는다. URL리졸버는 또한 docID의 쌍(pair)으로 이뤄진 링크 데이타베이스도 생성한다. 링크 데이타베이스는 모든 문서의 페이지랭크(PageRank) 값을 계산하는 데 사용된다.
소터(sorter)는 docID를 기준으로 정렬되어 있는(이건 단순화한 것이다, 섹션 4.2.5를 보라) 배럴을 wordID에 따라 재정렬해서 역인덱스(inverted index)를 만들어낸다. 이 작업은 임시 사용공간을 최소로 하기 위해 그 자리에서 수행된다. 소터는 또한 wordID 와 역인덱스 내에서의 옵셋(offsets) 목록을 만들어낸다. DumpLexicon이라고 불리우는 프로그램은 이 목록을 인덱서가 만들어낸 렉시컨(lexicon; 어휘목록)과 합해서 서쳐(searcher; 검색 애플리케이션)가 사용할 새로운 어휘목록을 만들어낸다. 서쳐는 웹 써버에 의해 구동되며 DumpLexicon에 의해 구축된 어휘목록, 역인덱스, 그리고 페이지랭크를 모두 이용해서 질의어에 응답한다.
4.2 주요 데이타 구조 (Major Data Structures)
구글의 데이타 구조는 대용량의 문서 컬렉션을 크롤링하고 인덱싱하고 적은 비용으로 검색할 수 있게 최적화되어 있다. 비록 수년에 걸쳐 CPU와 입출력 속도가 극적으로 좋아져 왔음에도 불구하고, 디스크 검색시간(disk seek)은 여전히 약 10 ms가 요구된다. 구글은 가능한 한 디스크 검색을 피하도록 디자인되었고, 이 점은 데이타 구조를 디자인하는 데 있어 상당한 영향을 줘왔다.
4.2.1 빅파일(BigFiles)
빅파일(BigFiles)은 여러 파일 시스템에 걸쳐 펼쳐져 있는 64비트 정수형 주소를 갖는 가상의 파일(virtual files)이다. 여러 파일 시스템에 할당되는 것은 자동으로 이뤄진다. 빅파일 패키지는 또한 파일 디스크립터(file descriptors)의 할당(allocation)과 할당해제(deallocation)를 자동으로 다루는데, 이것은 운영체계가 제공하는 것으로는 우리의 필요에 충분치 않았기 때문이다. 빅파일은 또한 기본적인 압축 옵션을 지원한다.
4.2.2 리파지토리(Repository; 저장소)
리파지토리는 개별 웹 페이지의 전체 HTML을 담고 있다.

각각의 페이지는 zlib(RFC1950 참고)을 이용하여 압축된다. 압축 테크닉 선택은 서로 상충관계(tradeoff)에 있는 속도와 압축율 선택의 문제다. 우리는 bzip이 제공하는 훨씬 더 높은 압축율대신 zlib의 속도를 선택했다. bzip의 리파지토리 압축율은 4:1인데 zlib은 3:1이다. 리파지토리 내에서 문서는 하나씩 순서대로 저장되며, 그림 2에서와 같이 docID, 길이, 그리고 url로 머리말이 붙여져있다. 리파지토리는 억세스하는 데 있어 그외 어떤 데이타 구조도 요구되지 않는다. 이렇게 함으로써 데이타 일관성을 유지할 수 있고 개발이 훨씬 쉬워지게 된다; 오직 리파지토리와 크롤러 에러 목록을 담은 파일만 있으면 모든 다른 데이타 구조를 재구축할 수 있다.
4.2.3 문서 인덱스(Document Index)
문서 인덱스는 개별 문서에 관한 정보를 유지한다. 이 인덱스는 docID 순서로 정돈된 고정 폭 ISAM(a fixed width ISAM;Index Sequential Access Mode) 인덱스이다. 각각의 엔트리에 저장되는 정보는 현재 문서의 상태, 리파지토리로의 포인터(pointer), 문서 첵섬(document checksum), 그리고 다양한 통계치 등을 포함한다. 만약 문서가 크롤링된 것이라면, 그 문서의 URL과 제목을 담고 있는 docinfo라는 이름의 가변 폭 파일(variable width file)로의 포인터도 담고 있을 것이다. 크롤링된 게 아니라면 URL만 담고 있는 URL리스트로의 포인터만 있을 것이다. 이렇게 디자인을 하기로 결정한 것은 합리적 수준의 컴팩트한 데이타 구조를 만들고 싶어서이고, 또한 검색을 하는 동안 한 번의 디스크 검색만으로 레코드를 가져올 수 있게 하고 싶어서이다.
추가적으로, URL을 docID로 변환하는 데 사용되는 파일이 있다. 이 파일은 URL 첵섬(checksums)과 그에 해당하는 docID의 목록으로, 첵섬을 기준으로 정렬되어 있다. 특정 URL의 docID를 찾고 싶다면, URL의 첵섬을 계산하여 첵섬 파일에 대하여 docID를 찾는 바이너리 검색(binary search)이 수행된다. 여러 개의 URL은 이 파일을 병합함으로써 docID로 일괄(batch; 뱃치) 변환될 수 있을 것이다. 이것이 URL리졸버가 URL을 docID로 바꿀 때 사용한 방법이다. 업데잇을 이처럼 뱃치 모드로 하는 것이 대단히 중요했는데 그렇게 하지 않으면 각 링크마다 매번 디스크 시크(seek)를 수행해야만 하기 때문이다. 이런 식이라면 디스크 하나로 우리가 갖고 있는 3억2200만 개의 링크 데이타셋을 처리하려면 한 달 이상이 걸릴 것이다.
4.2.4 렉시컨(Lexicon; 어휘목록)
렉시컨은 여러 가지 다른 형태를 갖고 있다. 초기 시스템으로부터의 중요한 변화 중 하나는 렉시컨이 합리적 가격의 메모리에 잘 들어맞는다는 것이다. 현 임플리멘테이션의 경우 메인 메모리가 256 MB인 머쉰의 메모리 상에 어휘목록을 유지할 수 있다. 현재 어휘목록은 1400만 단어(비록 약간의 희귀단어는 목록에 첨가되지 못했지만)를 담고 있다. 렉시컨은 두 부분으로 임플리멘테이션되어 있다 -- 단어 목록(사슬처럼 연결되어 있지만 각각은 널(null) 문자로 구분된)과 포인터의 해쉬 테이블로 구성되어 있다. 기타 다양한 기능을 위해 어휘목록에는 다른 부가적인 정보가 있는데, 그 부분에 대한 완전한 설명은 이 논문의 범위를 넘어선다.
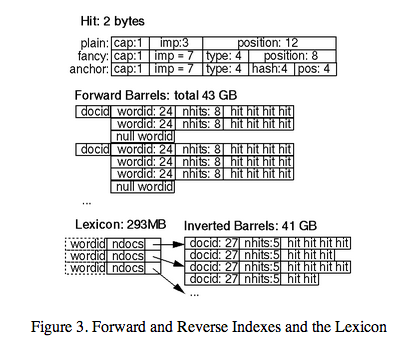
4.2.5 히트 리스트(Hit Lists)
히트 리스트는 특정 단어가 특정 문서에서 출현한 것의 목록으로, 단어의 위치, 폰트, 그리고 대소문자 정보를 포함한다. 히트 리스트는 포워드 인덱스나 역인덱스 양쪽 모두에서 대부분의 공간을 차지한다. 이 점 때문에, 히트 리스트는 가능한 한 효율적으로 표현하는 게 중요하다. 우리는 단어의 위치, 폰트, 그리고 대소문자 정보를 인코딩하는 여러 가지 대안을 고려했다 -- 단순 인코딩(3개의 정수 묶음), 컴팩트 인코딩(비트를 핸드 옵티마이즈해서 할당(a hand optimized allocation of bits)), 그리고 허프만 코딩(Huffman coding). 최종적으로 우리는 핸드 옵티마이즈드 컴팩트 코딩을 선택했는데, 그 방식이 단순 인코딩에 비해 공간을 훨씬 적게 필요로 했고 허프만 코딩보다 비트 처리를 훨씬 덜 필요로 했기 때문이다. 히트에 관한 세부사항은 그림 3에 있다.
우리가 사용한 컴팩트 인코딩은 각 히트에 대해 2 바이트를 사용한다. 히트에는 두 가지 유형이 있다: 팬시 히트(fancy hits)와 플레인 히트(plain hits). 팬시 히트는 url, 제목, 앵커텍스트(anchor text), 메타테그에서 히트가 있는 경우다. 플레인 히트는 그밖에 나머지다. 플레인 히트는 대소문자 비트, 폰트 크기, 그리고 문서 내의 단어 위치를 처리하는 12비트로 구성된다.(4095보다 큰 위치는 모두 4096으로 표지된다) 폰트 크기는 문서의 다른 부분과 비교한 상대적인 크기로 표시되며 3비트를 사용한다.(111은 팬시 히트임을 알리는 플랙(flag)이므로 실제 사용되는 것은 7개 값뿐이다) 팬시 히트는 대소문자 비트, 팬시 히트임을 알려주기 위해 7로 지정된 폰트 크기, 팬시 히트의 유형을 인코딩하기 위한 4비트, 그리고 위치를 나타내는 8비트로 구성되어 있다. 앵커 히트의 경우, 위치 비트인 8비트는 앵커 내의 위치를 처리하는 4비트와 앵커가 나타난 문서의 docID의 해쉬를 위한 4비트로 나뉜다. 이렇게 함으로써 특정 단어에 대한 앵커가 그다지 많지 않은 경우에 한해 제한적인 문장 검색을 하게 한다. 우리는 단어 위치와 docID 해쉬 필드를 보다 더 명확하게 보여줄 수 있는 방식으로 앵커 히트를 저장할 수 있는 방식으로 업데이트하고자 한다. 폰트 크기는 문서 나머지 부분과의 상대적 비교값을 사용했는데 왜냐하면 검색을 할 때, 문서 중 하나가 더 큰 폰트로 작성되어 있다고 해서 동일 문서를 다르게 랭크해서는 안 되기 때문이다.
히트 리스트의 길이는 히트 자신 앞에 저장한다. 공간을 절약하기 위해, 히트 리스트의 길이는 포워드 인덱스에서는 wordID와 연계하고 역 인덱스에서는 docID에 연결한다. 이렇게 해서 히트 리스트 길이를 포워드 인덱스에서는 8 비트, 역 인덱스에서는 5비트로 각각 제한한다.(wordID로부터 8 비트를 빌어올 수 있는 트릭들이 있다) 만약 길이가 그보다 길어서 맞지 않는다면 그 비트에서는 탈출 코드(escape code)를 사용하고, 다음 2 바이트에 실제 길이를 담는다.
4.2.6 포워드 인덱스(Forward Index)
포워드 인덱스는 사실 이미 부분적으로 정렬되어 있다. 그리고 여러 개의 배럴에 저장되어 있다.(우리는 64개의 배럴을 사용했다) 각각의 배럴은 일정 범위의 wordID를 저장 유지한다. 만약 어떤 문서에 있는 단어가 특정 배럴에 속한다면, 그 문서의 docID를 배럴에 기록하고 그 뒤에는 각 단어들에 대응되는 히트 리스트와 함께 wordID 목록을 기록한다. 이런 방식은 docID가 중복 저장되기 때문에 저장 공간을 조금 더 필요로 하지만 그 크기는 합리적 수준의 버킷(buckets) 숫자에 비춰보면 아주 작은 수준이며 소터(sorter)에 의해 수행되는 최종 인덱싱 단계에서 코딩 복잡성과 소요 시간을 현저하게 줄여준다. 게다가, 실제 wordID들을 저장하는 대신 각 wordID를 그 wordID가 속한 배럴의 최소값 wordID와의 상대적 차이로 기록한다. 이렇게 함으로써, 정렬되지 않은 배럴에 있는 wordID들은 단지 24비트만을 사용할 수 있고,히트 리스트 길이를 위한 8비트를 남겨둘 수 있다.
4.2.7 역인덱스(Inverted Index)
역인덱스(inverted index)는 포워드 인덱스와 동일한 배럴로 구성되는데, 차이점은 소터(sorter)에 의해 처리되어 있다는 점이다. 모든 유효한 wordID에 대해 렉시컨(lexicon)은 그 wordID가 속한 배럴로의 포인터를 갖고 있다. 그 포인터는 docID들의 리스트(doclist)와 이에 상응하는 히트 리스트들을 가리킨다. 이 doclist는 그 단어가 나타난 모든 문서를 나타내주고 있다.
중요한 이슈는 doclist에서 docID들을 어떤 순서로 보여줘야 하는가이다. 단순한 해결책은 docID를 기준으로 정렬하는 것이겠다. 이렇게 하면 복수 질의어에 대한 각기 다른 doclist들을 빠르게 병합할 수 있다. 또 다른 선택지는 개별 문서에서 그 단어가 얼마나 많이 나오느냐로 순위를 매겨 정렬하는 것이다. 그렇게 하면 질의어가 한 단어인 경우 쉽게 처리할 수 있으며 여러 단어 질의어에 대한 응답들도 가급적 시작 위치에 있게 할 것이다. 하지만 병합 과정이 무척 어려워진다. 또한 이렇게 하면 인덱스를 다시 만들어야 하는 랭킹 함수 변경을 해야 할 경우 개발 과정이 훨씬 어려워진다. 우리는 역인덱스 배럴을 두 세트로 만들어 유지함으로써 양자의 절충안을 택했다 -- 문서 제목이나 앵커 히트를 포함하는 히트 리스트 한 세트와 그밖의 모든 히트 리스트 세트로. 이렇게 함으로써, 일단 첫 번째 배럴 세트를 살펴 보고 충분한 매칭이 안 되면 보다 큰 두 번째 세트를 확인해 보게 한 것이다.
4.3 웹을 크롤링하기(Web Crawling)
웹 크롤러를 운용한다는 것은 도전적인 과제다. 성능과 신뢰성에 관한 까다로운 이슈들이 있으며, 또한 이보다 훨씬 중요한 사회적인 이슈들이 있다. 크롤링은 가장 취약한 애플리케이션인데 그 이유는 엄청난 숫자의 웹 써버와 상호작용을 해야 하며 시스템의 통제를 넘어서는 다양한 네임써버(name servers)와 인터액션을 해야 하기 때문이다.
억 단위 이상의 웹 페이지를 처리할 수 있게 확장하기 위해 구글은 분산화되어 있는 빠른 크롤링 시스템을 구축했다. 하나의 URL써버가 다수의 크롤러(통상은 3개)에 URL 목록을 제공한다. URL써버와 크롤러는 파이썬(Python) 언어로 만들었다. 각 크롤러는 대략 한 번에 300개의 연결을 열어둔다. 웹 페이지를 빠른 속도로 읽어들이기 위해서는 이렇게 해야 할 필요가 있다. 최고 속도에서는 4개의 크롤러를 사용해서 초당 100 페이지를 크롤링할 수 있다. 대략 초당 600K에 달하는 데이타를 읽어들이는 것이다. 성능상의 가장 큰 장애물은 DNS 검색이다. 각 크롤러는 각자 자신의 DNS 캐쉬를 유지해서 개별 문서를 크롤링하기 전에 DNS를 검색해야 할 필요가 없게 했다. 수백개의 연결은 다양한 상태일 수 있다: DNS를 검색하고 있거나, 호스트에 접속 중이거나, 요청을 보내고 있거나, 또는 응답을 받고 있을 수 있다. 이러한 점들 때문에 전체 시스템 중 특히 크롤러가 복잡한 요소다. 수많은 페이지를 상태에 맞게 하나씩 읽어들이고 또 이벤트들을 처리하기 위해 크롤러는 비동기IO(asynchronous IO)를 사용한다.
50만개 이상의 써버에 접속해서 수천만 개의 로그 기록을 만들어내게 되면 상당한 정도의 이메일와 전화를 받게 된다는 게 확인되었다. 온라인 상에는 엄청난 숫자의 사람들이 있으므로 그 중엔 항상 크롤러가 뭔지 모르는 사람들이 있을 수밖에 없다. 그런 것은 처음 봤을 것이기 때문이다. 거의 매일 우리는, "와!! 제 웹 사이트의 여러 페이지를 보고 가셨네요! 보니까 어떻던가요?"와 같은 이메일을 받았다. 또한 robots exclusion protocol을 모르는 사람들도 많기 때문에, "이 페이지는 저작권의 보호를 받으며 인덱싱되서는 안 됩니다"라는 문구를 이용하면 자신의 페이지가 보호된다고 생각하는 경우가 있는데, 물론 크롤러는 그런 문구를 이해하기 어려운 것이다. 또한, 거대한 데이타에 대한 작업이다 보니, 전혀 예상치 못 한 일이 생기기도 했다. 예를 들면, 온라인 게임을 크롤링하려하는 것. 게임을 크롤링하게 되니까 게임 속에 있는 수많은 쓰레기 메세지를 읽어들이게 됐다! 이 문제는 쉽게 해결할 수 있었다. 하지만 이 문제점은 우리가 수천만 페이지를 다운로드하고서야 나타난 문제였다. 웹 페이지와 써버의 엄청난 다양성 때문에,크롤러를 실제 인터넷의 큰 부분에 대해 확인해 보지 않고서는 테스트하는 게 사실상 불가능하다. 그리고 항상 전체 웹 중 한 페이지에서만 일어나는 애매모호한 수백가지의 문제점 때문에 크롤러가 충돌하고, 심지어는, 예측불가능한 잘못된 방식으로 실행되기까지 한다. 인터넷의 상당 부분을 접근하고자하는 시스템은 대단히 강력하게(robust) 디자인되어야 하며 신중하게 테스트되어야 한다. 크롤러와 같이 커다랗고 복잡한 시스템은 거의 항상 문제를 일으키기 때문에 이메일을 읽고 새롭게 나타난 문제점들을 해결하는 데 집중하는 상당한 규모의 리소스가 필요하다.
4.4 웹 인덱싱(Indexing the Web)
파싱(parsing) -- 전체 웹을 대상으로 구동되도록 디자인된 파서라면 반드시 엄청난 종류의 가능한 에러를 다루어야만 한다. 이들 에러는 HTML의 오자에서부터 태그의 중간에 있는 수 킬로바이트의 O, 비 아스키 문자들, 한없이 깊게 파고들어가는 HTML 테그, 그밖에 사람이 상상할 수 있는 모든 종류의 도전 등을 망라한다. 속도를 극대화하기 위해서, CFG 파서를 생성하는 YACC를 사용하는 대신, 우리는 자체 스택(stack)과 함께 준비한 어휘 분석기(lexical analyzer)를 생성할 수 있도록 flex를 사용하였다. 합리적인 수준의 속도로 구동되면서 매우 강력한 수준으로 이 파서를 개발하는 것은 상당한 양의 작업이 필요하다.
문서를 베럴로 인덱싱해 넣기 -- 각각의 문서가 파싱된 후에는 여러 개의 배럴로 인코딩되어 들어간다. 모든 단어는 메모리 상의 해쉬 테이블을 사용해서 wordID로 변환된다 -- 렉시컨(lexicon;어휘목록). 렉시컨 해쉬 테이블에 새롭게 추가되는 것은 파일에 기록된다. 일단 단어들을 wordID로 변환하고 나면, 현재 문서에서 그 단어들이 나타나는 경우 히트 리스트로 변환해서 포워드 배럴에 기록한다. 인덱싱 단계의 병렬화에 있어서 주된 난점은 렉시컨이 공유되어야만 한다는 점이다. 렉시컨을 공유하는 대신, 우리는 기초 어휘목록에 포함되지 않는 다른 모든 단어들을 1400만 단어를 한도로 로그에 기록하는 접근법을 택했다. 이렇게 함으로써 복수의 인덱서를 병렬로 실행할 수 있고 그밖의 단어가 기록된 작은 크기의 로그 파일은 최종 인덱서 하나로 처리할 수 있는 것이다.
정렬(sorting) -- 역인덱스를 생성하기 위해서, 소터는 각각의 포워드 베럴을 wordID를 기준으로 정렬해서 제목과 앵커 히트에 대한 역 배럴 그리고 풀 텍스트의 역 배럴을 만들어낸다. 이 과정은 한 번에 한 배럴씩 진행해서, 최소한의 임시 저장공간만 필요토록 했다. 또한, 복수의 소터를 사용하는 것으로써 우리는 소팅 단계를 가급적 많은 머쉰을 사용할 수 있게 병렬화했는데, 이렇게 함으로써 다른 버킷(buckets)들을 동시에 처리할 수 있다. 배럴은 메인 메모리에 들어 맞지 않기 때문에, 소터는 wordID와 docID에 기초하여 메모리에 맞는 바스켓으로 배럴을 더욱 세분화한다. 그러면 소터는 각각의 바스켓을 메모리로 불러 들이고, 정렬한 다음, 그 내용물을 짧은 역 배럴과 풀 역 배럴에 기록해 넣는다.
4.5 검색(Searching)
검색의 목표는 효율적으로 질 높은 검색 결과를 제공하는 것이다. 많은 대형 상업적 검색 엔진들은 효율성 측면에서는 큰 발전을 이뤄온 것처럼 보인다. 그러므로, 비록 우리 솔루션이 약간의 노력만 더 하면 상업적인 스케일로 확장가능하다고 믿고 있음에도 불구하고, 본 연구에서는 검색의 질적인 측면에 더 포커스를 맞춰왔다. 구글 질의어 평가 과정은 그림 4와 같다.

응답 시간에 제한을 두기 위해, 일단 일정 숫자(현재는 4만 개)의 관련 문서가 발견되면 서쳐는 자동으로 그림 4의 8단계로 건너 뛴다. 이것은 덜 최적화된(sub-optimal) 결과가 제공될 수도 있음을 의미한다. 우리는 현재 이 문제를 해결할 다른 방법을 찾고 있는 중이다. 과거에는, 히트를 페이지랭크(PageRank)에 따라 정렬했는데, 상황이 개선된 것처럼 보였다.
4.5.1 랭킹 시스템(The Ranking System)
구글은 일반적이 검색엔진들보다 훨씬 더 많은 웹 문서에 관한 정보를 유지관리한다. 각 히트 리스트는 단어 위치, 폰트, 그리고 대소문자 정보를 포함하고 있다. 추가적으로, 앵커 텍스트로부터의 히트와 문서의 페이지랭크도 요소로 넣고 있다. 이런 모든 정보를 조합해서 순위를 매기는 것은 어려운 일이다. 우리는 어떤 특정 요소도 지나치게 많은 영향을 미치지 않도록 랭킹 기능을 디자인하고자 했다. 먼저, 단순한 케이스를 생각해 보자 -- 한 단어 질의어의 경우. 단일 단어로 된 질의어에 대해 어떤 문서를 랭킹하기 위해서, 구글은 그 단어에 대한 그 문서의 히트 리스트를 살펴 본다. 구글은 각 히트가 여러 유형일 수 있다고 생각하며(제목, 앵커, URL, 큰 폰트의 플레인 텍스트, 작은 폰트의 플레인 텍스트,...) 각각은 자신만의 유형가중치(type-weight)를 갖고 있다. 유형 가중치는 유형을 기준으로 인덱싱된 벡터를 구성한다. 구글은 각 유형의 히트가 히트리스트에 몇 번 나오는지 센다. 그 다음 각 카운트는 카운트 가중치(count-weight)로 변환된다. 카운트 가중치는 최초에는 카운트에 따라 선형적으로 증가하지만 곧 급격히 줄어들어 어느 수준부터는 더 이상의 카운트는 의미가 없어진다. 그 다음 카운트 가중치 벡터와 유형 가중치 벡터의 내적(dot product)을 이용해서 그 문서의 IR 점수를 계산한다. 최종적으로, IR 점수는 페이지랭크와 결합해서 문서에 대한 최종 랭크를 제공하게 된다.
복수 단어 검색의 경우, 상황은 훨씬 복잡해진다. 그 경우에는 문서 내에서 복수 단어에 대한 히트들이 서로 가깝게 나타난 경우를 멀리 떨어진 경우보다 더 높은 가중치를 주기 위해서 복수의 히트 리스트를 동시에 훓어 보야야만 한다. 가까운 히트를 함께 매치하기 위해 복수의 히트 리스트로부터의 히트들을 매치 업 한다. 모든 매칭된 히트 세트에 대해 근접성(proximity)을 계산한다. 근접성은 어떤 문서(또는 앵커) 내에서 히트가 얼마나 멀리 떨어져 있는가에 기초하지만 10개의 다른 값을 갖는 "상자(bins)"로 분류되는데, 이들은 정확한 구절 매치(phrase match)로부터 "터무니 없는" 것까지의 범위를 갖는다. 카운트는 히트의 유형에 대해서뿐만 아니라 각각의 유형-근접성에 대해서도 계산된다. 모든 유형-근접성 쌍은 유형-근접성-가중치(type-prox-weight)를 갖는다. 카운트는 카운트 가중치로 변환해서 카운트-가중치와 유형-근접성-가중치의 내적을 구해 IR 점수를 계산한다. 이들 모든 값들과 행렬들은 따로 마련된 디버그 모드(debug mode)를 사용한 검색 결과 출력시 함께 표시될 수 있게 했다. 그렇게 보여지는 것은 랭킹 시스템을 개발하는 데 있어 대단히 큰 도움이 되었다.
4.5.2 피드백(Feedback)
랭킹 함수는 유형-가중치, 유형-근접성-가중치 등과 같은 많은 파라미터(parameters)를 갖고 있다. 이들 파라미터의 올바른 값을 찾아내는 것은 마법과 같은 것이어서, 우리는 이것을 검색 엔진의 사용자 피드백 미케니즘을 이용해 알아내보고자 한다. 신뢰할 수 있는 사용자의 경우 원한다면 모든 검색 결과에 대해 평가를 해볼 수 있다. 그리고 그 피드백은 저장된다. 그래서 랭킹 함수를 수정할 때 과거 랭킹했던 모든 검색에 대해 이것이 미친 영향을 알 수 있다. 완전한 것과는 거리가 있겠지만, 이렇게 함으로써 랭킹 함수를 바꾼 것이 어떻게 검색 결과에 영향을 주는지에 관해 아이디어를 얻을 수 있다.
5. 결과와 성능 (Results and Performance)
검색엔진의 가장 중요한 측정 기준은 검색 결과의 품질이다. 완전한 사용자 평가는 본 논문의 범위를 넘어서지만, 우리 자신이 구글을 이용한 경험으로는 대부분의 검색어에 대해서 메이져 상업적 검색엔진보다 더 나은 결과를 보여주었다.

페이지랭크(PageRank), 앵커 텍스트(anchor text), 근접성(proximity)을 이용하는 하나의 예시로, 구글의 "bill clinton"에 대한 검색결과를 그림 4에 실었다. 이 결과는 구글의 특징 몇 가지를 보여주고 있다. 검색 결과는 서버를 기준으로 클러스터되어져 있다. 이렇게 하는 것은 검색 결과 묶음을 읽어나가면서 걸러내는 데 상당한 도움이 된다. 검색 결과의 다수가 백악관 도메인 whitehouse.gov로부터 오고 있는데 이것이 아마도 "Bill Clinton" 검색에서 합리적으로 기대하는 바일 것이다. 현재로는 대부분의 메이져 상업 검색엔진들은 whitehouse.gov로부터의 결과를 전혀 보여주고 있지 않는데, 이건 훨씬 부정확한 것이다. 첫 번째 검색결과에는 제목이 없다는 데 주목하자. 이렇게 된 이유는 이것이 크롤링된 게 아니기 때문이다. 대신, 구글은 앵커 텍스트에 의존해서 이것이 질의어에 대한 좋은 대답일 것이라고 결정한 것이다. 비슷하게, 5번째 결과는 이메일 주소인데, 이것 역시 크롤링될 수 없는 것이다. 이 또한 앵커 텍스트의 결과다.
이러한 검색결과들이 모두 다 납득할 만한 수준의 고품질 페이지들이고, 마지막 체크까지는 깨진 링크는 하나도 없었다. 가장 큰 이유는 이들이 모두 높은 페이지랭크 값을 갖고 있기 때문이다. 페이지랭크는 붉은 색의 퍼센트 숫자로 표기되어 있고 옆에는 바 그래프가 있다. 마지막으로, 검색 결과에 '클린턴이 아닌 빌'이나 '빌이 아닌 클린턴'이 없다는 것을 볼 수 있다. 이것은 등장한 단어의 근접성에 큰 중요성을 부과한 것 때문이다. 물론, 검색엔진의 품질을 제대로 테스트하려면 여기서 설명하기엔 부족한 방대한 유져 스터디나 검색 결과 분석이 필요할 것이다. 대신, 이 글을 읽는 독자들이 직접 구글을 사용해 보시길 권한다. 주소는 http://google.stanford.edu.
5.1 저장공간 요구사항 (Storage Requirements)
검색 품질외에도, 구글은 웹의 크기가 성장해 나가는 것에 맞게 비용 효율적으로 확장할 수 있도록 디자인되어 있다. 이와 관련된 한 가지 측면은 저장 공간을 효율적으로 사용하는 것이다. 표 1은 구글의 저장공간 요구사항과 몇 가지 통계치 명세를 보여주고 있다. 압축을 한 덕분에 리파지토리(repository) 총 크기는 약 53 GB로 전체 데이타의 약 1/3을 약간 넘는 수준이다. 현재의 디스크 가격에서 이 정도면 리파지토리가 유용한 데이타를 저장하는 상대적으로 저렴한 소스라고 할 수 있다. 더 중요한 것은, 검색엔진이 사용하는 데이타 총량에 요구되는 공간도 이와 비슷한 수준의 약 55 GB라는 점이다. 게다가, 대부분의 질의어는 숏 역익덱스만 사용해서 처리될 수 있다. 문서 인덱스의 더 나은 인코딩과 압축을 통해, 고품질의 웹 검색엔진은 최신 피씨의 경우 7 GB의 드라이브에 적합될 수 있을 것이다.

5.2 시스템 성능 (System Performance)
검색엔진이 크롤링과 인덱싱을 하는 데 있어 효율적인가 하는 문제는 중요하다. 이를 통해 최신의 정보에 맞게 유지할 수 있고 시스템에 대한 대규모 변화를 준 경우의 테스트를 할 때도 상대적으로 빠르게 할 수 있기 때문이다. 구글은, 주된 작업이란 것이 크롤링과 인텍싱, 그리고 정렬하는 것이다. 크롤링이 얼마나 걸리는가를 계측하는 것은 어렵다. 왜냐하면 디스크는 가득 차버리고, 네임 서버는 충돌할 수도 있고, 기타 다른 여러 가지 문제 때문에 시스템이 멈출 수 있기 때문이다. 대략, 2600만 페이지(에러 포함)를 다운로드하는 데 약 9일 정도 걸린다. 하지만, 일단 시스템이 원활하게 구동하기 시작하면, 속도는 훨씬 빨라진다. 그래서 마지막 1100만 페이지를 다운로드하는 것은 63시간이면 충분하고, 이것은 결국 평균을 내보면 하루에 400만 페이지를 약간 넘는 정도로 초당 48.6 페이지를 처리하는 것이 된다. 우리는 인덱서와 크롤러를 동시에 운용한다. 인덱서는 크롤러보다 약간 더 빠르다. 이것은 아마도 우리가 인덱서가 병목현상의 주체가 되는 걸 막으려고 이를 최적화하는 데 많은 신경을 썼기 때문일 것이다. 최적화라는 것은 문서 인덱스에 대한 대규모의 업데이트, 그리고 로컬 디스크에 핵심적인 데이타 구조를 사용한 것 등을 포함한다. 인덱서는 대략 초당 54 페이지를 처리한다. 소터도 병렬적으로 동시 구동이 될 수 있는데, 4개의 머쉰을 사용하고 있고, 소팅의 총과정은 대략 24시간이 소요된다.
5.3 검색 성능 (Search Performance)
검색 성능을 향상시키는 것은 현재까지로는 우리 연구의 주된 포커스는 아니다. 현 시점의 구글은 1~10초 사이에 대부분의 질의어에 대해 결과를 내놓고 있다. 그 시간은 대부분 NFS 상에서 디스크 IO를 처리하는 시간이다.(디스크는 여러 대의 머쉰에 펼쳐져 있기 때문) 게다가, 구글은 질의어 캐싱(query caching)이나 자주 나오는 질의어에 대한 하부 인덱스(subindices) 등 일반적인 최적화 수단을 전혀 사용하고 있지 않다. 우리는 분산화와 하드웨어, 소프트웨어 개선 그리고 알고리즘 향상을 통해 구글의 속도를 높이고자 한다. 우리 목표는 초당 수백 개의 질의어를 처리할 수 있게 되는 것이다. 표 2는 현재 구글에서 몇 가지 질의어의 처리 시간을 예시하고 있다. 캐쉬된 IO를 이용한 경우의 속도 향상을 보여주기 위해 같은 질의어를 반복해서 결과를 비교해보았다.

6. 결과 (Conclusions)
구글은 확장가능하게 디자인된 검색엔진이다. 구글의 최고 목표는 급속하게 성장하는 월드와이드웹에 맞게 고품질의 검색 결과를 제공하는 것이다. 구글은 검색 품질을 높이기 위해 페이지랭크나 앵커 텍스트, 근접성 정보 등 많은 정보를 이용한다. 또한 구글은, 웹 페이지를 모으고, 인덱싱하고, 그것을 대상으로 검색 질의 처리를 수행하는 완결된 아키텍쳐이다.
6.1 미래에 할 작업
대형 웹 검색엔진은 복잡한 시스템으로 많은 해야 할 일들이 남아 있다. 우리의 일차적 목표는 검색 효율을 향상시키고 약 1억 페이지까지 확장하는 것이다. 효율성을 향상하기 위한 단순한 방법에는 질의어 캐싱(query caching), 효율적인 디스크 할당, 하부 인덱스 사용 등이 있다. 많은 연구가 필요한 또 다른 분야로 업데이트가 있다. 오래된 페이지중 어떤 것을 다시 크롤링할 것인지 그리고 어떤 새로운 페이지를 크롤링해야 하는지 결정할 수 있는 더 스마트한 알고리듬이 반드시 필요하다. 이 목표를 위한 연구는 Jungho Cho, Hector Garcia-Molina, Lawrence Page의 "Efficient Crawling Through URL Ordering" 논문을 통해 이뤄졌다. 유망한 연구 분야 중 하나는 검색 데이타베이스를 구축하는 데 있어 프락시 캐시(proxy cache)를 사용하는 것이다. 왜냐하면 이것은 수요대응형(demand-driven)이기 때문이다. 우리는 상업적 검색엔진에서 지원하고 있는 간단한 기능들, 예를들어 불리언 검색(boolean operators), 부정어 검색(negation), 스테밍(stemming) 같은 것을 추가할 계획이다. 한편, 상관성 피드백(relevance feedback)이나 클러스터링(clustering) 같은 기능들은 이제 막 연구하고 있는 상태다.(구글은 현재 호스트네임에 기초한 단순 클러스터링만 지원한다) 우리는 또한 사용자 컨텍스트(예를 들어 사용자의 위치 같은)에 대한 지원과 검색결과의 요약(summarization)을 지원할 계획을 갖고 있다. 그리고 링크 구조와 링크 텍스트의 사용을 더 확장하기 위한 작업도 진행 중이다. 간단하게 실험을 해보니까 사용자의 홈페이지나 북마크에 가중치를 더 줌으로써 페이지랭크를 개인화할 수 있었다. 링크 텍스트와 관련해서는, 링크 텍스트 그 자체외에도 링크를 둘러 싼 텍스트를 사용하는 것을 실험 중이다. 웹 검색엔진은 연구 아이디어를 위한 대단히 풍부한 환경이라고 할 수 있다. 연구할 것들이 너무나 많기 때문에 미래에 해야 할 작업을 다룬 이런 단락이 가까운 시일에 짧아지기는 힘들 것이다.
6.2 고품질 검색 (High Quality Search)
오늘날 웹 검색엔진 사용자가 직면한 가장 큰 문제는 검색 결과의 품질이다. 검색 결과가 즐거움을 주고 사용자의 지평을 넓혀주는 경우도 종종 있기는 하지만, 사용자를 짜증나게 하고 소중한 시간을 허비하게 하는 경우도 많다. 예를 들어, 가장 인기가 있는 검색엔진 중 하나는 "Bill Clinton"이라는 검색어에 대해 결과 최상위에 있는 것이 Bill Clinton Joke of the Day: April 14, 1997이다. 구글은 웹의 급속한 성장에 맞게 정보를 쉽게 찾을 수 있도록 고품질 검색을 제공할 수 있게 디자인되어 있다. 이를 위해 구글은 링크 구조와 링크(앵커) 텍스트로 구성된 하이퍼텍스 관련 정보를 대폭 사용하고 있다. 구글은 또한 근접성(proximity) 정보와 폰트 정보도 사용한다. 검색엔진을 평가하는 문제는 어렵지만, 우리 주관적 판단으로는 구글이 다른 상업적 검색엔진보다 더 고품질의 결과를 보여준다고 생각한다. 페이지랭크를 이용한 링크 구조의 분석을 통해 구글은 웹 페이지들의 품질을 평가한다. 링크 텍스트를 링크가 무엇을 가르키는 것인지를 설명해주는 것으로 사용함으로써 관련성 있는 검색결과를(그리고 어느 정도까지는 고품질의 결과를) 보여줄 수 있게 한다. 마지막으로, 근접성 정보를 사용함으로써 많은 질의어에 대해 관련성을 높여준다.
6.3 확장가능한 아키텍쳐 (Scalable Architecture)
검색의 질 문제와 함께, 구글은 확장할 수 있게 디자인되어 있다. 시간과 공간 양자 모두에서 효율적이어야 하고 전체 웹을 다루기 위해서는 상수 요소(constant factors)들이 매우 중요하다. 구글을 임플리멘테이션하면서 우리는 CPU, 메모리 억세스, 메모리 용량, 디스크 검색(disk seek), 디스크 쓰루풋(disk throughput), 디스크 용량, 네트웍 IO 등에서 병목현상이 있음을 알게 되었다. 구글은 다양한 작업 수행 중에 나타나는 이들 병목현상을 극복할 수 있게 진화되어 왔다. 구글의 주요 데이타구조는 저장 공간을 효율적으로 사용한다. 또한, 크롤링, 인덱싱, 정렬 과정은 웹의 상당 부분(2400만 페이지)에 대한 인덱스를 구축하는 것이 1주일 미만이면 가능하다. 우리는 1억 페이지의 인덱스를 한 달 안에 구축할 수 있기를 기대하고 있다.
6.4 연구 도구 (A Research Tool)
고품질 검색엔진이 되는 것외에도, 구글은 하나의 연구 도구이기도 하다. 구글이 수집한 데이타는 이미 많은 다른 연구논문이 학회에 제출되는 것으로 귀결되었고 현재 진행 중인 것도 많다. Serge Abiteboul and Victor Vianu의 "Query and Computation on the Web" 같은 최근 논문은 웹을 로컬 머쉰에 갖고 있지 않으면 질의어에 응답하는 데 많은 한계점이 있음을 보여주었다. 이것은 구글이나 이와 유사한 시스템이 하나의 가치있는 연구 툴일 뿐만 아니라 광범위한 적용에 있어서도 필수적인 것임을 뜻한다. 우리는 구글이 전세계의 검색자와 연구자들을 위한 리소스가 되길 희망하며, 차세대 검색엔진 기술을 점화하는 역할을 하길 기대한다.
8. 부록 A: 광고와 복합적인 동기들 (Advertising and Mixed Motives)
현 시점, 상업적 검색엔진의 지배적인 비즈니스 모델은 광고다. 광고 비즈니스 모델의 목표는 사용자에게 질 좋은 검색을 제공하는 것과 항상 상응하는 것은 아니다. 예를 들어, 우리가 시험구축한 검색엔진에 "휴대폰"을 검색하면 결과 최상위로 "운전자 주의에 관한 휴대폰의 영향"이라는, 운전 중 휴대폰 사용이 운전자 주의를 뺏는 것과 그 위험성을 자세히 설명해주는 연구를 보여준다. 이것이 결과의 첫 번째로 뜨는 이유는 그 문서가 웹 상의 인용 중요성(citation importance)을 유사하게 구현한 페이지랭크 알고리듬에 의하면 높은 중요성을 갖고 있기 때문이다. 휴대폰 광고를 보여주는 것으로 돈을 받은 검색엔진이라면 우리 시스템이 보여주는 결과를 광고주에게 납득시키기 어려울 것이다. 이런 류의 이유 그리고 다른 미디어와의 과거 경험 때문에, 우리는 광고 수익을 기반으로 한 검색엔진은 원초적으로 광고주에 편향될 것이고 사용자 니즈와 거리가 멀 것이라고 생각한다.
검색엔진을 평가하는 것은, 심지어 전문가에게도 어려운 일이기 때문에 검색엔진의 편향성은 특별히 더 은밀하게 퍼진다. 좋은 예가 OpenText로, 특정 검색어의 검색결과 상위에 오를 수 있는 권리를 파는 것으로 알려져있다. 이런 유형의 편향성은 광고보다 훨신 더 은밀하다. 왜냐하면 누가 그 자리에 있을 '자격'이 있는지와 누가 목록에 오르기 위해 돈을 지불하려 하는지가 불분명하기 때문이다. 이 비즈니스 모델은 결국 엄청난 논란으로 귀결되었고, OpenText는 문을 닫을 수밖에 없었다. 하지만 덜 노골적인 편향성은 시장에서 살아남을 가능성이 크다. 예를 들어, 검색엔진은 자신과 '친밀한' 회사들의 검색 결과에 작은 요소를 추가할 수 있을 것이고 반대로 경쟁자들과 관련된 결과에는 어떤 요소를 빼버릴 수 있는 것이다. 이런 형태의 편향성은 찾아내기가 극히 어려우면서도 시장에 심대한 영향을 줄 수 있다. 더 나쁜 것은, 광고 수익은 종종 나쁜 검색 결과를 보여줄 유인이 될 수 있다는 점이다. 예를 들어, 대표적 검색엔진에 대형 항공사의 이름을 넣어 검색하면 항공사의 홈페이지가 뜨지 않는다는 점을 우리는 알게 되었다. 값비싼 광고를 주면 검색어에 항공사 이름을 연결해 주기 때문에 나타나는 일이다. 좋은 검색엔진이라면 이런 식의 광고를 요구하지 않아야 할 것이이다. 물론 그 결과 항공사로부터의 수익은 얻지 못 할 수 있겠지만 말이다. 일반적으로 말하자면, 소비자 관점에서 좋은 검색엔진이란 자신이 원하는 바를 찾는 데 있어 광고를 가급적 적게 보게 되는 것이다. 이것은 물론 현존하는 검색엔진들의 광고 수익 기반 비즈니스 모델을 훼손한다. 하지만, 고객이 다른 제품에서 자기 제품으로 바꾸기를 원하는 광고주나 완전히 새로운 무엇을 알리고 싶어하는 광고주는 항상 있는 법이다. 어쨌든 광고 이슈는 많은 복합적인 인센티브를 불러일으키는 문제이기 때문에, 투명성이 높으면서도 학문적 영역에서도 활용 가능한 경쟁력 있는 검색엔진을 갖는 건 대단히 중요하다고 생각한다.
9. 부록 B: 확장성 (Scalability)
9.1 구글의 확장성 (Scalability of Google)
우리는 구글이 머지 않아 1억 페이지를 목표로 확장될 수 있게 디자인해왔다. 얼마 전 그 정도 수준을 다룰 수 있는 디스크와 머쉰을 배송받기도 했다. 시스템에서 시간을 잡아 먹는 모든 과정은 병렬화되고 목표를 향해 선형적으로 진행된다. 이 부분은 크롤러나 인덱서, 소터 등을 포함하는 것이다. 우리는 또한 대부분의 데이타 구조가 확장성 문제를 우아하게 처리할 수 있을 것으로 본다. 하지만, 1억 페이지 수준에서는 일반적인 운영체제(현재로는 솔라리스와 리눅스를 이용하고 있다)에서 거의 대부분 한계점에 이를 것으로 생각된다. 어드레서블 메모리(addressable memory), 열려진 파일 디스크립터(file descriptor)의 갯수, 네트웍 소켓과 밴드위쓰, 그리고 다른 많은 문제들이 여기에 해당한다. 1억 페이지 이상으로 확장하는 것은 그래서 우리 시스템의 복잡성을 대폭 증가시킬 것으로 생각하고 있다.
9.2 중앙집권적 인덱싱 아키텍쳐의 확장성 (Scalability of Centralized Indexing Architecture)
컴퓨터의 성능이 향상됨에 따라, 적정한 비용으로도 대용량의 텍스트를 색인화하는 게 가능해졌다. 물론, 비디오와 같은 밴드위쓰가 많이 필요한 미디어들이 광범위하게 확산되고 있다. 하지만, 비디오 같은 미디어에 비해 텍스트를 만들어내는 것은 소요되는 비용이 적기 때문에 텍스트는 여전히 계속 널리 퍼져나가고 있을 것이다. 또한, 우리는 연설이나 발표 등을 텍스트로 바꿔주는 음성 인식 기능을 조만간 갖게 될 것이어서, 활용가능한 텍스트의 양은 더욱 커질 것이다. 이런 모든 점들은 중앙집권화된 인덱싱의 놀라운 가능성을 보여준다. 예시를 하나 들어 보자. 우리가 1년 동안 미국 내의 모든 사람이 쓴 모든 것을 인덱싱한다고 하자. 미국 인구를 2억5000만 명으로 가정하고 그들이 매일 평균 10k를 쓴다고 하자. 그러면 이것은 약 850 테라바이트가 된다. 또한 1 테라바이트를 인덱싱하는 것이 감내할 수 있는 수준의 비용으로 가능하다고 가정하자. 그리고 텍스트 상에 수행되는 색인화 수단이 복잡성에 있어 선형적이거나 거의 선형적이라고 가정하자. 이런 모든 가정을 통해 우리는, 어떤 성장 팩터를 가정하면 합리적 수준의 비용에서 850 테라바이트를 인덱싱하는 것이 얼마나 오래 걸릴 지를 계산할 수 있다. 무어의 법칙은 1965년에 나온 것으로 프로세서 파워가 18개월마다 두 배가 된다는 것이다. 이 법칙은 놀라울 정도로 실제 현상과 일치했고 이것은 단지 프로세서뿐만 아니라 디스크 같은 다른 주요 시스템 요소에서도 그러했다. 무어의 법칙이 미래에도 유효할 것이라고 가정해 본다면, 앞으로 15년 뒤 또는 10번의 반복 뒤면 작은 회사가 감내할 수 있는 비용으로도 1년 동안 미국 내의 모든 사람이 쓴 모든 것을 인덱싱할 수 있게 된다. 물론, 하드웨어 전문가들은 무어의 법칙이 향후 15년 동안 계속해서 유효할 수 있을 것인가에 대해 의심을 하기도 한다. 하지만, 우리가 가정해 본 예시의 일부분만 달성하더라도 많은 흥미로운 중앙집권화된 애플리케이션들을 생각해 볼 수 있을 것이다.
참고문헌 (References)
1. Serge Abiteboul and Victor Vianu, Queries and Computation on the Web. Proceedings of the International Conference on Database Theory. Delphi, Greece 1997.
2. S.Chakrabarti, B.Dom, D.Gibson, J.Kleinberg, P. Raghavan and S. Rajagopalan. Automatic Resource Compilation by Analyzing Hyperlink Structure and Associated Text. Seventh International Web Conference (WWW 98). Brisbane, Australia, April 14-18, 1998.
3. Junghoo Cho, Hector Garcia-Molina, Lawrence Page. Efficient Crawling Through URL Ordering. Seventh International Web Conference (WWW 98). Brisbane, Australia, April 14-18, 1998.
4. Luis Gravano, Hector Garcia-Molina, and A. Tomasic. The Effectiveness of GlOSS for the Text-Database Discovery Problem. Proc. of the 1994 ACM SIGMOD International Conference On Management Of Data, 1994.
5. Jon Kleinberg, Authoritative Sources in a Hyperlinked Environment, Proc. ACM-SIAM Symposium on Discrete Algorithms, 1998.
6. Massimo Marchiori. The Quest for Correct Information on the Web: Hyper Search Engines. The Sixth International WWW Conference (WWW 97). Santa Clara, USA, April 7-11, 1997.
7. Oliver A. McBryan. GENVL and WWWW: Tools for Taming the Web. First International Conference on the World Wide Web. CERN, Geneva (Switzerland), May 25-26-27 1994.
http://www.cs.colorado.edu/home/mcbryan/mypapers/www94.ps
8. Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd. The PageRank Citation Ranking: Bringing Order to the Web.
9. Brian Pinkerton, Finding What People Want: Experiences with the WebCrawler. The Second International WWW Conference Chicago, USA, October 17-20, 1994. http://info.webcrawler.com/bp/WWW94.html
10. Ellen Spertus. ParaSite: Mining Structural Information on the Web. The Sixth International WWW Conference (WWW 97). Santa Clara, USA, April 7-11, 1997.
11. Proceedings of the fifth Text REtrieval Conference (TREC-5). Gaithersburg, Maryland, November 20-22, 1996. Publisher: Department of Commerce, National Institute of Standards and Technology. Editors: D. K. Harman and E. M. Voorhees. Full text at: http://trec.nist.gov/
12. Ian H Witten, Alistair Moffat, and Timothy C. Bell. Managing Gigabytes: Compressing and Indexing Documents and Images. New York: Van Nostrand Reinhold, 1994.
13. Ron Weiss, Bienvenido Velez, Mark A. Sheldon, Chanathip Manprempre, Peter Szilagyi, Andrzej Duda, and David K. Gifford. HyPursuit: A Hierarchical Network Search Engine that Exploits Content-Link Hypertext Clustering. Proceedings of the 7th ACM Conference on Hypertext. New York, 1996.
'테크' 카테고리의 다른 글
| 월드와이드웹(WWW)을 만든 팀 버너스 리(Tim Berners-Lee) 인터뷰 (0) | 2020.07.02 |
|---|---|
| p2p(Peer-to-peer)와 자유주의 (0) | 2020.06.30 |
| 리눅스를 만든 리누스 토발즈(Linus Torvalds) 인터뷰 (1) | 2020.06.20 |
| 네트웍 시대의 시장구조 (Varian 교수 논문 번역) (0) | 2020.06.12 |
| 구글 페이지랭크: 웹에 질서를 부여한다, 논문 (0) | 2020.04.29 |